Neural Networks
- AI, ML, deep learning, neural netsnot yet tested
- Layers, neurons, embeddingsnot yet tested
- Gradient descent, loss, dropoutnot yet tested
- Supervised learning and AlphaGonot yet tested
In 1943, Warren McCulloch and Walter Pitts modelled a neuron as a binary threshold unit — fire if the weighted sum of inputs exceeds a threshold — and showed that networks of such units could compute any logical function. In 1958 Frank Rosenblatt built the Perceptron, a single-layer network with a learning rule, and the New York Times described it as the embryo of a machine that would eventually walk, talk, and be conscious. Eleven years later, Minsky and Papert proved single-layer networks could not even learn XOR, the press coverage collapsed, and the field entered its first long winter. The fix — multi-layer networks trained with backpropagation — was rediscovered several times before Rumelhart, Hinton, and Williams gave it canonical form in 1986. A second winter followed in the 1990s. The deep-learning revolution arrived in 2012, when AlexNet won ImageNet by a margin that ended the argument.
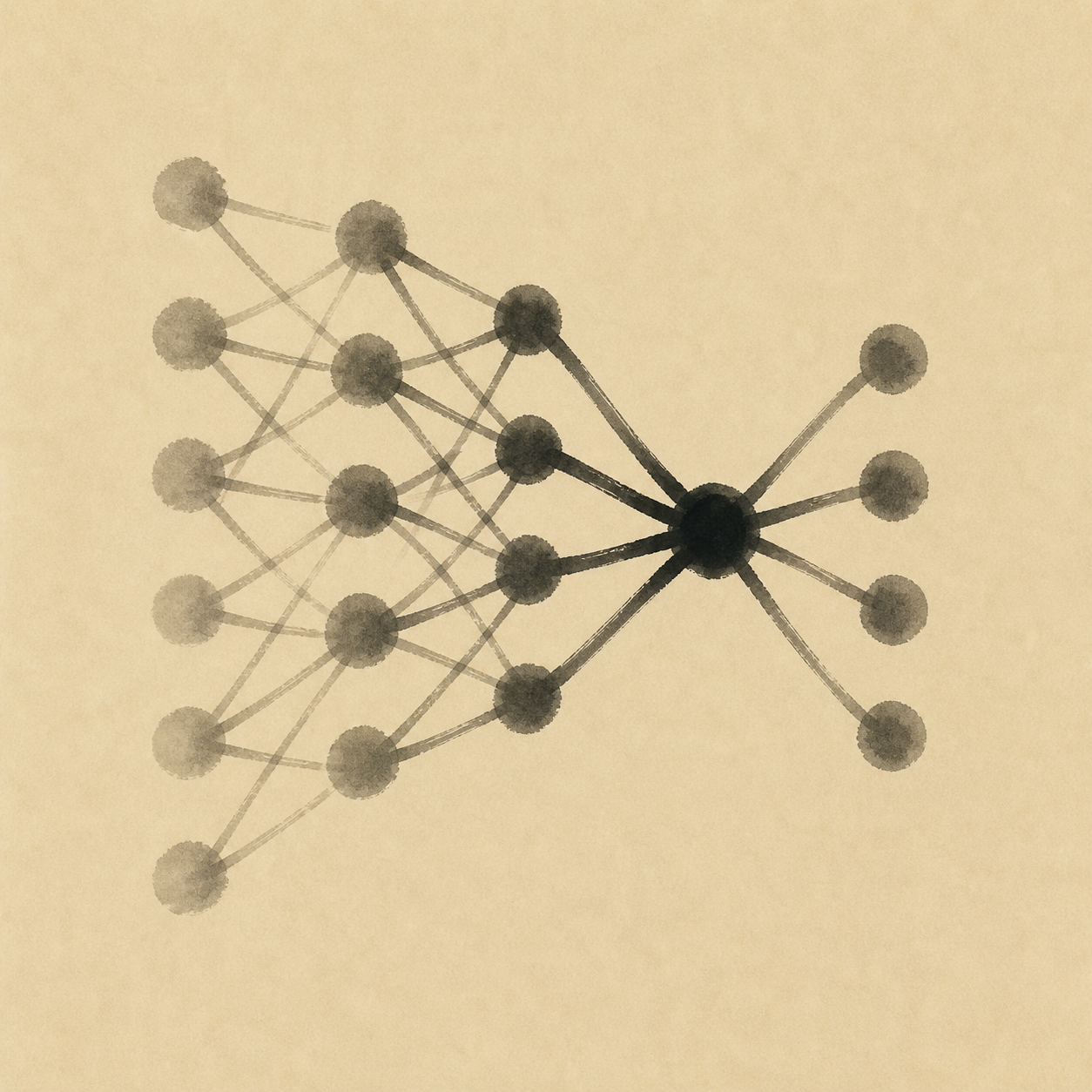
The atom is the artificial neuron: it takes its inputs, forms a weighted sum, adds a bias, and passes the result through a nonlinear activation — a loose caricature of a biological neuron's integrate-and-fire behaviour, not a copy of its messy electrochemistry. Wire many such units side by side into a layer, stack the layers so each feeds the next, and a neural network is exactly that: a stack of linear transformations (multiply by a weight matrix, add a bias) interleaved with nonlinear activations (sigmoid historically, ReLU/GELU now). The nonlinearity is what matters — without it, any stack of layers collapses into a single linear map, no more expressive than the perceptron that failed at XOR. Depth is what buys richness: early layers learn coarse features, later ones compose them into something abstract, so the network discovers its own representation of the data rather than being handed one. The universal approximation theorem (Cybenko 1989, Hornik 1991) guarantees that with enough hidden units such a network can approximate any continuous function — but says nothing about how many, or how to find the weights. The practical answer is backpropagation: define a loss measuring how wrong the network is, then use the chain rule to send the gradient of that loss back through every weight, nudging each one in the direction that reduces the loss — a process pursued under its own concept, gradient descent. Iterate over the data until the loss stops falling — the deeper the stack, the harder this once was, since gradients could vanish before reaching the early layers, that better activations and initialisation later eased. Variants (momentum, Adam, learning-rate schedules) and stochastic gradient descent on mini-batches turn what is mathematically straightforward into something that scales to networks with hundreds of billions of parameters. The deep surprise of the last decade is that this very simple recipe, applied at scale, keeps producing capabilities the theory does not predict.