Neuronale Netze
- AI, ML, deep learning, neural netsnoch nicht geprüft
- Layers, neurons, embeddingsnoch nicht geprüft
- Gradient descent, loss, dropoutnoch nicht geprüft
- Supervised learning and AlphaGonoch nicht geprüft
1943 modellierten Warren McCulloch und Walter Pitts das Neuron als binäre Schwelleneinheit — feuere, wenn die gewichtete Summe der Eingaben einen Schwellenwert übersteigt — und zeigten, dass Netze solcher Einheiten jede logische Funktion berechnen können. 1958 baute Frank Rosenblatt das Perzeptron, ein einschichtiges Netz mit Lernregel, und die New York Times beschrieb es als den Embryo einer Maschine, die einst gehen, sprechen und bewusst sein werde. Elf Jahre später bewiesen Minsky und Papert, dass einschichtige Netze nicht einmal XOR lernen können, das mediale Interesse brach ein, und das Feld trat in seinen ersten langen Winter. Die Reparatur — mehrschichtige Netze, mit Backpropagation trainiert — wurde mehrfach neu entdeckt, bis Rumelhart, Hinton und Williams ihr 1986 die kanonische Form gaben. Ein zweiter Winter folgte in den 1990ern. Die Deep-Learning-Revolution kam 2012, als AlexNet ImageNet mit einem Vorsprung gewann, der die Diskussion beendete.
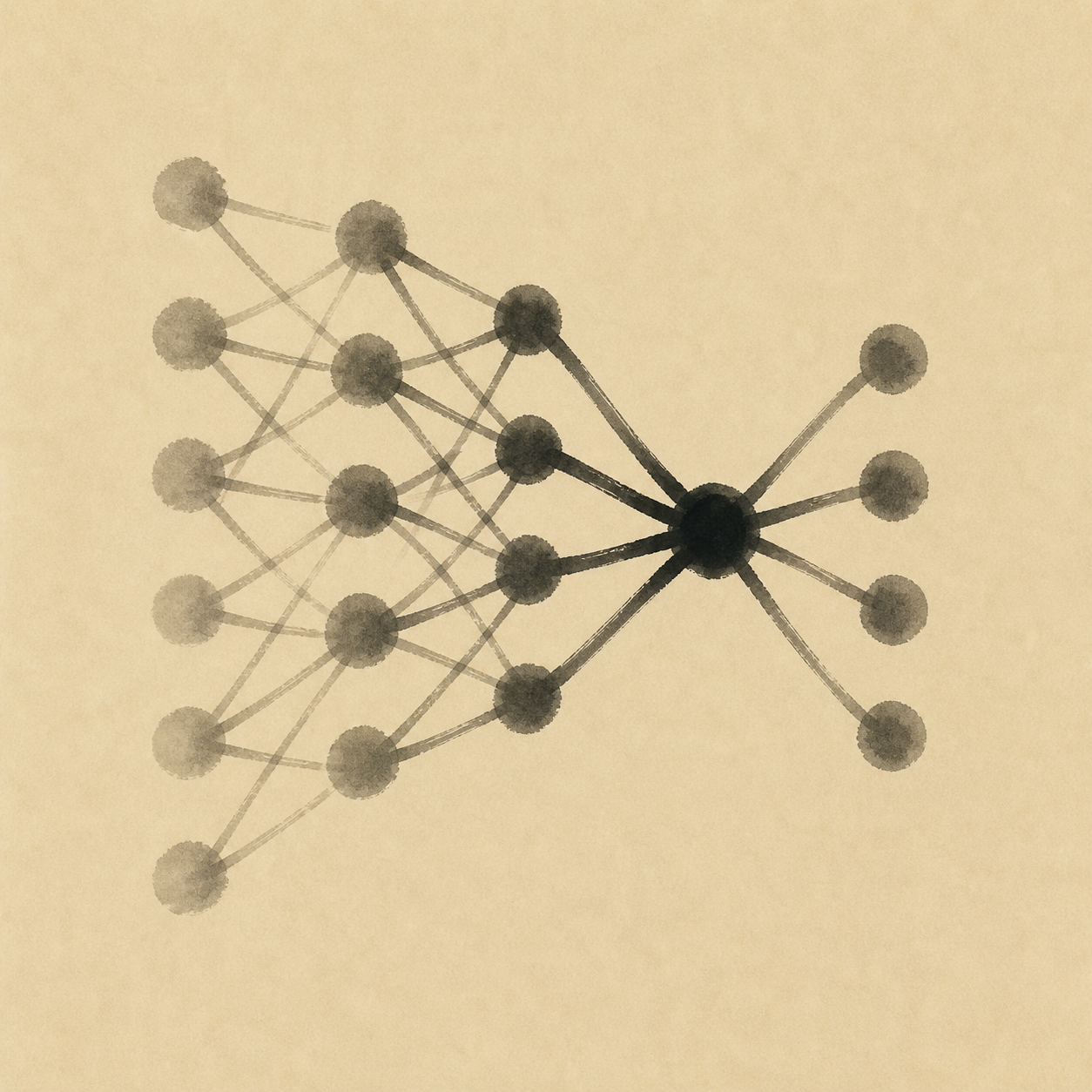
Das Atom ist das künstliche Neuron: Es nimmt seine Eingaben, bildet eine gewichtete Summe, addiert einen Bias und schickt das Ergebnis durch eine nichtlineare Aktivierung — eine grobe Karikatur des Integrate-and-fire-Verhaltens eines biologischen Neurons, keine Kopie seiner unordentlichen Elektrochemie. Schaltet man viele solcher Einheiten nebeneinander zu einer Schicht, stapelt die Schichten so, dass jede die nächste speist, dann ist ein neuronales Netz genau das: ein Stapel linearer Transformationen — mit einer Gewichtsmatrix multiplizieren, einen Bias addieren —, durchsetzt mit nichtlinearen Aktivierungen (historisch Sigmoid, heute ReLU/GELU). Auf die Nichtlinearität kommt es an — ohne sie fällt jeder Stapel von Schichten in eine einzige lineare Abbildung zusammen, nicht ausdrucksstärker als das Perzeptron, das an XOR scheiterte. Tiefe ist es, die den Reichtum bringt: frühe Schichten lernen grobe Merkmale, spätere setzen sie zu etwas Abstraktem zusammen, sodass das Netz seine eigene Repräsentation der Daten findet, statt eine vorgesetzt zu bekommen. Der universelle Approximationssatz (Cybenko 1989, Hornik 1991) garantiert, dass ein solches Netz mit hinreichend vielen versteckten Einheiten jede stetige Funktion annähern kann — er sagt aber nichts darüber, wie viele es braucht oder wie man die Gewichte findet. Die praktische Antwort ist die Backpropagation: definiere einen Verlust, der misst, wie falsch das Netz liegt, schicke dann mit der Kettenregel den Gradienten dieses Verlusts durch jedes Gewicht zurück und stoße jedes in die Richtung, die den Verlust verkleinert — ein Vorgang, der unter einem eigenen Begriff verfolgt wird, dem Gradientenabstieg. Iteriere über die Daten, bis der Verlust nicht mehr fällt — je tiefer der Stapel, desto schwerer fiel das einst, weil die Gradienten verschwinden konnten, ehe sie die frühen Schichten erreichten, eine Schwierigkeit, die bessere Aktivierungen und Initialisierung später linderten. Varianten (Momentum, Adam, Lernraten-Pläne) und der stochastische Gradientenabstieg auf Mini-Batches machen aus dem mathematisch Geradlinigen etwas, das auf Netze mit Hunderten Milliarden Parametern skaliert. Die tiefe Überraschung des vergangenen Jahrzehnts ist, dass dieses sehr einfache Rezept, im großen Maßstab angewandt, immer weiter Fähigkeiten hervorbringt, die die Theorie nicht vorhersagt.